By signing in, you agree to 古古的後端筆記's terms of service and privacy policy.
By signing in, you agree to 古古的後端筆記's terms of service and privacy policy.

古古
2025/04/08
Elasticsearch 可以說是長年霸佔「全文搜尋」排行榜的第一名,不管是在使用者的產品開發上、還是在內部的 log 系統中,也都常常能看見 Elasticsearch 的身影,因此這篇文章我們就來介紹一下,Elasticsearch 到底是什麼吧!
首先 Elasticsearch 其實是由兩個單字 Elastic 和 Search 所組成,因此念法上就會唸成 Elastic Search,只不過官方的產品名稱是全部縮寫在一起而已。
而 Elasticsearch 本身是一個強大的「全文搜尋」(Full-Text Search)工具,也就是一個「能夠讓你自己架設搜尋引擎」的工具。所以簡單的說,Elasticsearch 的目標就是「讓使用者能夠快速的從一堆數據中,找到他想要的資料在哪裡」,也就是搜尋引擎最重要的作用了。
不過在我們開始介紹 Elasticsearch 到底是強在哪裡之前,我們可以先回頭來看一下,在 Elasticsearch 還沒有誕生之前,我們是如何使用 SQL 資料庫來實作「查詢」的功能的。
想像一下,假設現在你要開發一個「評論」的網站,因此在你的資料庫中,就會有一張 review 的 table,裡面記錄了每一筆評論的詳細內容:
| review_id | review_text(評論內容) |
|---|---|
| 1 | I jumped out the brown fox |
| 2 | hello how are you |
那麼問題來了,假設現在使用者輸入了 brown,要你查詢出帶有 brown 的評論,這時候你要怎麼實作?
最直覺的做法,就是使用「SQL 的模糊搜尋 LIKE %」,從這些評論中找出到底哪些評論中包含 brown 這個單字,因此通常就會寫出類似於下方的 SQL 語法,去資料庫中查詢所有評論。
SELECT * FROM review WHERE review_text LIKE "%brown%"
雖然上述的作法能夠查詢出帶有 brown 單字的評論,但是這個查詢的效率實在是太差了!因為模糊搜尋沒辦法使用 index 來加速查詢效率,只能呆呆的一筆一筆數據去比對,因此縱使這個方法勉勉強強能夠解決查詢的問題,但是卻解的不夠漂亮。
所以為了更好的解決這個問題,Elasticsearch 就被發明出來了!
在 Elasticsearch 中,一樣是會先對每一筆 review 評論建立一筆數據(在 Elasticsearch 中稱為「文件」),並且因為 Elasticsearch 是屬於 NoSQL 資料庫,所以會使用 JSON 格式來儲存該文件。
[
{ "review_id": 1, "review_text": "I jumped out the brown fox" },
{ "review_id": 2, "review_text": "hello how are you" }
]
其實到這邊其實都跟上面的 SQL 資料庫一模一樣,只是 Elasticsearch 換個方式用 JSON 儲存而已,到目前為止沒有任何的差別。
不過!!重點來了!!Elasticsearch 之所以能夠快速的查詢出「帶有 brown」的評論,就是因為 Elasticsearch 在插入一筆文件時,會預先對該文件建立「反向索引」(Inverted Index),因此之後就可以借助「反向索引」的力量,快速的找出相關評論。
舉例來說,當 Elasticsearch 插入一筆數據 hello how are you 時,他除了正常的插入一筆文件之外,他同時也會將 hello how are you 拆分成許多不同的小單字,譬如說會拆分成 hello、how、are、you 這四個字,並且 Elasticsearch 會將這些單字「對應」到該筆評論數據上。
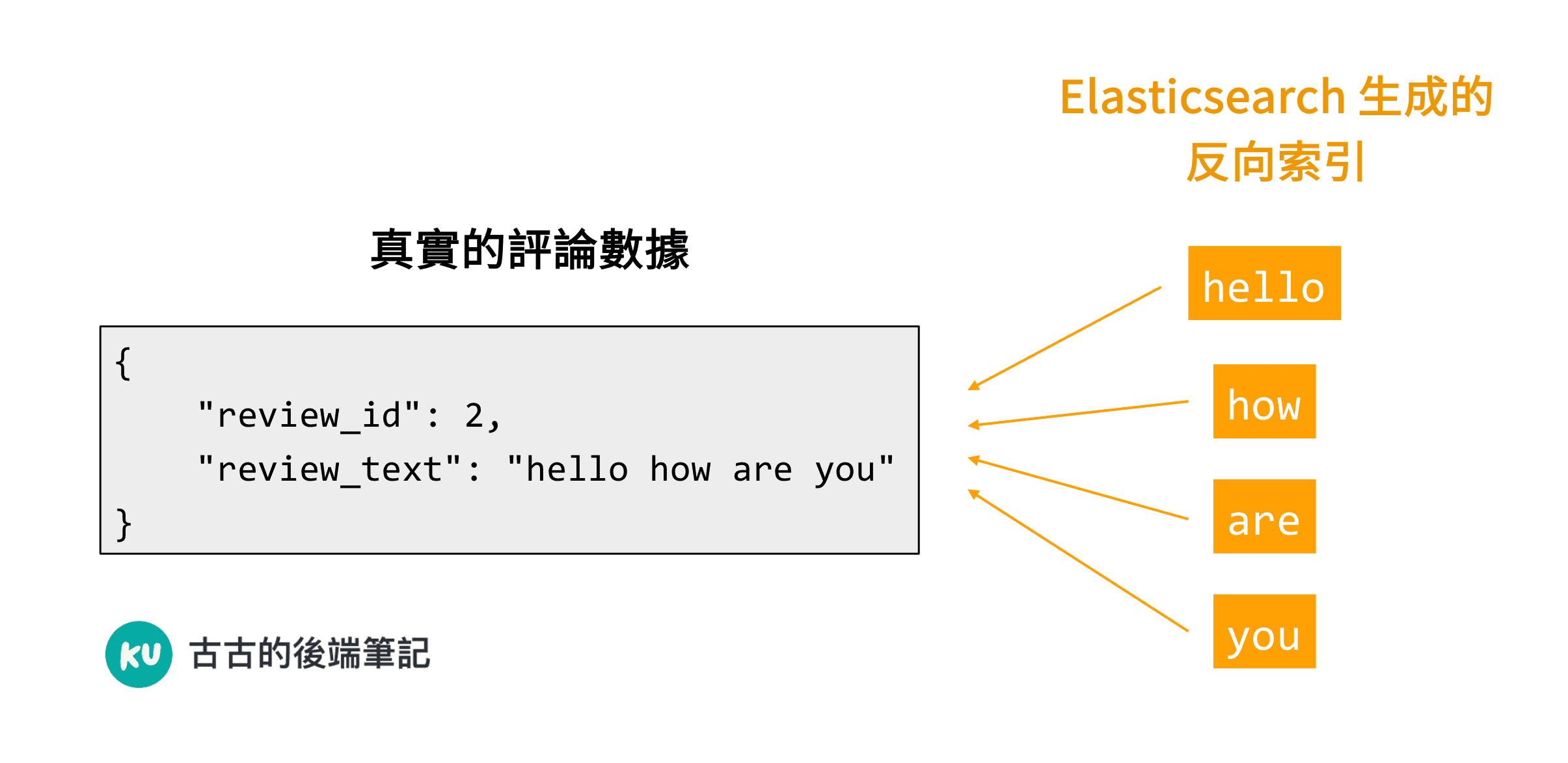
因此後續當使用者查詢 hello 或是查詢 are 時,Elasticsearch 就可以去檢查反向索引,如果有任何一個命中的話(譬如說命中 hello 這個反向索引),那麼就可以根據反向索引,去找出該索引指向的真實的數據(也就是 hello how are you 這個評論),這樣子就可以快速的在大量的資料中,去找到我們想要的數據了!
也因為在整個 Elasticsearch 的世界中,他不僅要儲存每一筆真實的評論數據之外,Elasticsearch 同時也需要為每一筆評論數據生成對應的反向索引,因此佔用的數據空間會比一般的 SQL 資料庫還要多,不過這其實也是演算法中典型的「用空間換取時間」的概念,即是先對數據進行預處理,將數據處理成好查詢的方式,等到未來需要時就可以馬上查詢,就可以達到「降低查詢時間」的終極目標了!
了解了 Elasticsearch 中最最最核心的「反向索引」的概念之後,我們再回頭來看 Elasticsearch 的介紹時,就可以比較看得懂了。
所謂的 Elasticsearch,他是一個強大的「全文搜尋」(Full-Text Search)工具,目標是讓我們可以從大量的數據中,快速找到想要的資料在哪裡。而 Elasticsearch 之所以可以做到這件事,就是因為他使用了「反向索引」(Inverted Index)的設計,先對數據進行預處理,因此才能夠在查詢時達到比傳統 SQL 資料庫更高的效率。
也因為 Elasticsearch 的專長是「全文搜尋」,所以一般通常會將他用來「架設搜尋引擎」,因此像是旅遊攻略、評論、社群貼文、電商產品…等等諸如此類的查詢,背後都很適合使用 Elasticsearch 來實作!
圖片來源: Elasticsearch 官網
而除了一般的功能開發之外,Elasticsearch 也很常拿來用在內部系統中,最常見的就是用來「收集所有系統的 log」,這樣子 DevOps 或是後端工程師就可以搭配 Kibana、Grafana 之類的 UI 介面,從 Elasticsearch 中直接查詢 log 的資料,就不用再登入每一台 server 中去找 log 了!
所以總結來說,只要牽扯到「全文搜尋」,基本上就是 Elasticsearch 的天下(當然 FAANG 大廠自行研發的搜尋引擎除外,他們的數據量真的太大,應該不是用 ES),並且內部的 log 系統通常也都是用 ELK 三兄弟來建置,所以了解一下 Elasticsearch 的用法絕對是很吃香的!
大家如果對 Elasticsearch 有興趣的話,後續也可以參考 Elastic 官網的文件教學,或是我很久很久以前也有寫過一些 Elasticsearch 的文章,大家有興趣的話也可以參考看看~(不過這些文章年代有點久遠,可能很多東西已經不適用了,後續有時間我再來把這部分重寫一下)。
最後再跟大家補充一個我經歷過的 Elasticsearch 反向索引的真實故事…
前面有提到,「反向索引」就是會預先把真實的數據 hello how are you 拆分成一個一個的小單字 hello、how、are、you,並且 Elasticsearch 會將這些單字「對應」到該筆數據上,而這個「拆分單字」的過程,稱為「分詞」(或是「斷詞」),而就是這個「分詞」,搞的我非常痛苦啊🥹…
首先 Elasticsearch 中的分詞預設都是以英文為主,所以 hello how are you 就可以根據空白鍵很簡單的進行拆分,但是如果你的 input 是中文的話,那就是災難的開始惹!!!
舉例來說,假設你的 input 是 我想吃小籠包,那麼 Elasticsearch 預設會拆分成 我、想、吃、小、籠、包 這 6 個字,這就會造成一個現象,就是當使用者查詢「LV 包包」時,因為 包 命中了…所以可能就會出現 我想吃小籠包 的神奇回覆….🥹(使用者會覺得合理嗎?好問題)。
即使使用 Elasticsearch 內建的 CJK(中日韓)分詞器,最終產生的效果也不太好:
POST _analyze
{
"analyzer": "cjk",
"text": "我想吃小籠包"
}
拆分成 [我想, 想吃, 吃小, 小籠, 籠包]
也因為 Elasticsearch 對中文的支援真的太慘烈了,所以 GitHub 上甚至有一個 16.9k star 的專案 analysis-ik,專門就是在做中文分詞,用了這個之後才分得比較合理(拍謝我有點搞不懂 Elasticsearch 現在怎麼裝 plugin,沒辦法實際測試,但應該就是會分詞出 小籠包 這個單字)。
所以大家如果後續想要拿 Elasticsearch 來實作中文的全文搜尋的話,建議一定要安裝這個 analysis-ik 的 plugin,對中文的分詞才會有比較明顯的改善(在此也感謝開源社區的大大們的貢獻🙏)。
這篇文章我們先介紹了什麼是全文搜尋(Full-Text Search),並且也透過 SQL 資料庫所面臨的困境,介紹 Elasticsearch 實際要解決的問題是什麼,希望可以幫助大家了解 Elasticsearch 的運作邏輯,搞懂反向索引(Inverted Index)的核心概念是什麼。
如果你對後端技術有興趣的話,也歡迎免費訂閱《古古的後端筆記》電子報,每週二為你送上一篇後端技術分享,那我們就下一篇文章見啦!
補充:我開設的 Spring Boot 零基礎入門、Spring Security 零基礎入門、GitHub 免費架站術 已在 Hahow 平台上架啦!輸入折扣碼「HH202603KU」即可享 83 折優惠 。