By signing in, you agree to 古古的後端筆記's terms of service and privacy policy.
By signing in, you agree to 古古的後端筆記's terms of service and privacy policy.

古古
2024/08/24
最近實在是看到太多 AI 的專有名詞了(ex: NLP、LLM、RAG),雖然我不搞 AI,但是稍微理解一下這些名詞在幹嘛還是有必要的,不然搞得好像全世界都在追一場很好看的劇,但是自己卻完全跟不上🥹。
所以這篇文章就會從頭來介紹一下 AI 的概念和邏輯(不需要任何程式背景也能看得懂),以及介紹常見的 AI 名詞,那麼我們就開始吧!
在談 LLM、RAG、GPT 這類的 AI 名詞之前,首先最最最重要的,是要先搞懂他們是要解決什麼問題。
這一系列 AI 的名詞,他們最根本的,是要解決「自然語言處理」的問題,而這個白話來說的話,就是要讓這些 AI 們「能夠說人話」(我們平常說的語言就是自然語言)。
像是在 AI 出現之前的時代,程式的運作是非常直覺的,工程師會寫一堆 if...else... 的判斷句,就是「當什麼事情發生時….程式就做什麼反應」。
所以在以前的年代,工程師就會寫出 if 有人說 "你好",程式就輸出 "Hello World" 這種程式,所以假設到時候,真的有人來說了 “你好”,那麼程式就會輸出 “Hello World” 這個字串,就是這麼簡單直覺暴力(所以這也是為什麼以前的客服機器人很笨,因為他就是只看得懂特定的句子,然後回覆固定的罐頭回答)。
但是自從 ChatGPT 出現之後,世界就開始變得不一樣了!
所謂的 ChatGPT,他是屬於一種生成式 AI,而他最大的不同點,就是「他會自己決定他要回覆什麼答案」。
所以當我們使用了 ChatGPT 之後,工程師就再也不用寫出 if 有人說 "你好",程式就輸出 "Hello World" 這種死板的程式了,工程師要做的,反而是告訴 ChatGPT 各式各樣的情境,讓 ChatGPT 自己去旁觀學習這樣。
所以譬如說工程師可能就會輸入下面這兩段對話給 ChatGPT:
A:你好
B:哈囉你好,你吃飽了沒?
A:還沒,正要去吃,你要一起嗎?
B:好啊!走吧
C:你好
D:心情不好,滾
C:別這樣嘛,走請你吃飯
D:你請客,謝謝
而當 ChatGPT 在「旁觀」完這兩段對話之後,他心中可能就會對於 “你好” 這兩個字,有自己的理解(這就像是人類在學習一樣,小時候都是透過旁觀父母的行為,決定自己的成長人格)。
所以下一次當你對 ChatGPT 說 “你好” 的時候,他的反應可能會是:
你:你好
ChatGPT:滾
又或是
你:你好
ChatGPT:哈囉滾
所以對於 ChatGPT 會回答什麼,你是完全不會預先知道的,甚至就連養出他的工程師也不知道他會回什麼😂,因為實際上工程師所做的,就只是輸入一大堆片段的對話範例,讓 ChatGPT 自己去感悟理解而已。
也因為對於每一個 ChatGPT 的模型而言,他們都是獨一無二的孩子,所以每一個孩子都會針對「同樣的對話範例」,會有「不一樣的理解」,而這個不斷拿範例對話去給 ChatGPT 旁觀學習的過程,就是俗稱的「訓練模型」。
所以實際上 ChatGPT 能夠長成什麼樣子,初始的範例對話是影響非常大的(就跟父母的言行對於孩子的影響很大一樣),所以這也是為什麼 ChatGPT 剛上市的時候常常被吐嘈中文很奇怪,估計就是因為初始的範例對話數據很少中文,啊就父母不會講中文,孩子不會講中文也很合理吧🤣🤣🤣。
所以到這邊先小結一下的話,就是 ChatGPT 所要解決的問題,就是要解決「自然語言處理(NLP)」的問題,而這個白話來說的話,就是要讓 AI「能夠說人話」。
至於 ChatGPT 的解決方法,就是透過不斷的輸入初始的範例數據,去「訓練 ChatGPT 的模型」,進而養出一個獨一無二的孩子(ex: GPT-3、GPT-4、GPT-4o…等),然後再來比較看看誰養的好這樣(天下父母心,我家的孩子就是要比別人家的好!)。
OK 在了解了 ChatGPT 要解決的是「自然語言處理」的問題之後,接下來要理解 LLM 和 RAG 就比較容易了。
其實在「自然語言處理」這個領域中,有一個分類,叫做 LLM(Large Language Models),也就是「大型語言模型」,只要是透過前面所提到的「不斷輸入初始化的範例數據,去訓練一個語言模型出來」的流程,那這個被訓練出來的模型,就叫做「大型語言模型(LLM)」。
所以其實 ChatGPT 在定義上,就是屬於 LLM 分類中的一種實作,只不過因為 ChatGPT 實在太紅了,所以他的傳播度才大於 LLM 這樣,但是在定義上,LLM 是比較廣泛的定義,但凡是被訓練出來的語言模型,就都可以是屬於 LLM 的一種。
所以像是目前市面上常見的 Gemini、GPT-4、Claude…等等,這些都是一個一個的大型語言模型(只是父母不同人而已,像是 Google、OpenAI…等),所以這些語言模型,就都是屬於 LLM 的一種實作。
所以簡單的說的話,LLM 就是「大型語言模型」,而市面上常見的 AI 產品,就都是屬於 LLM 中的一種實作,目的都是為了解決「自然語言」的問題(就是要讓 AI 說人話)。
而至於 RAG,就是比較新的概念了。所謂的 RAG,是一種結合 「大型語言模型」+「外部數據來源」 的技術。
舉個例子來說的話,假設 Google、OpenAI 他們透過很大量的初始範例對話,生成了一個一個的語言模型 Gemini、GPT-4…出來,而當你真的訂閱了這個模型來用的時候,你就會發現,怎麼 AI 所回答出來的內容,好像都是幾個月前的內容,就沒辦法回答最近兩天的內容這樣。
譬如說 GPT-4 只能告訴你:「籃球比賽的規則是什麼」,但是他卻沒辦法告訴你:「昨天獲勝的 NBA 球隊是哪一隻」,因為在 GPT-4 的初始訓練數據裡面,並沒有昨天獲勝的 NBA 球隊,所以他就不懂,所以他就沒辦法告訴你到底是誰獲勝。
而如果要解決這個問題的話,最直觀的想法,可能是「啊那就把昨天獲勝的 NBA 球隊也拿去訓練一下 GPT-4 不就好了?」,老實說拿著新數據重新去訓練 GPT-4 這條路是可行的,但是成本代價太高,所以基於成本考量,一般不太會這樣做。
所以為了要解決這個問題,RAG 就出現了!
所謂的 RAG,可以把他想像成是一個補丁包,就是你訂閱了一個 GPT-4 來用之後,你可以再跟他說:「這裡有昨天的 NBA 比賽數據,啊你不用訓練自己沒關係,你把他當小抄,如果我來問你 NBA 的比賽情況,你就順便看一眼這個小抄,然後再回答我就好」。
所以當我們在 GPT-4 這個模型之上,再去添加了 RAG 之後,就可以讓這個 GPT-4 在「不需要重新訓練模型」的情況下,也能夠「理解最新的客製化數據」,這樣子不僅可以省下許多成本,也可以達到取得到最新數據的目的了。
也因為 RAG 他是一種結合「大型語言模型」+「外部數據來源」的技術,讓 GPT-4 就像是得到了一堆小抄一樣,可以知曉外部數據中的內容。所以目前 RAG 比較常見的用法,就是透過 RAG 的技術,將 GPT-4 和企業內部的數據結合在一起,讓 GPT-4 變身成為一個知曉企業內部數據的強大語言模型!
有關 RAG 和語言模型的介紹,也可以參考下圖 OpenAI 對 LLM optimization context 的介紹,裡面就有提到,如果想要「加強 Context(上下文)的準確度」,那麼除了要設置 Prompt 之外,也可以透過 RAG 來加強。
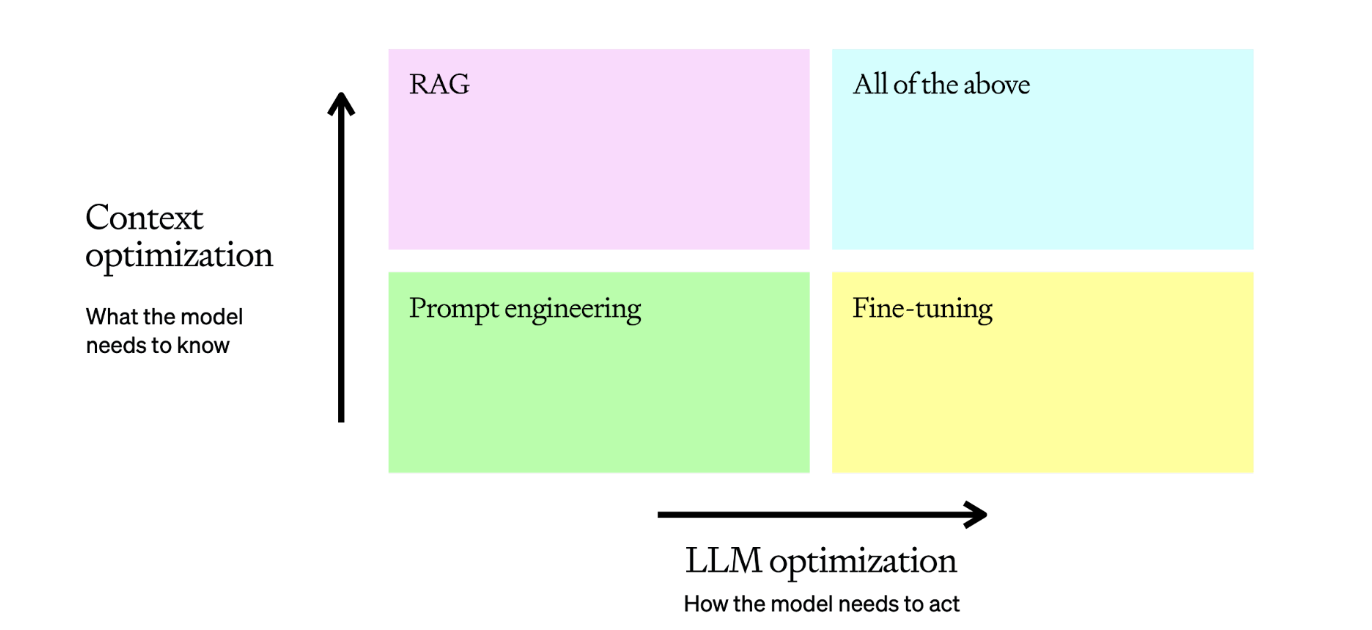
所以總結來說的話,RAG 可以說是一個省錢 + 客製化模型的新武器,我們是可以透過外掛一堆外部數據,來補足語言模型對於客製化數據(ex: NBA 昨天比賽結果、企業內部的數據)的精準理解。
這篇文章我們先去介紹了 ChatGPT 的運行邏輯是什麼,並且也有去介紹 AI 中常見的名詞,像是 NLP、LLM、RAG…等等,就希望讓大家可以對這些 AI 的專有名詞,有一個初步的了解。畢竟 AI 可以說是全球一起在追的劇,多少了解一下概念還是會很有幫助的💪。
雖然這篇文章是對於 AI 的介紹,但我的本業是後端工程師,後續還是會專注在後端技術的介紹上,所以如果你對後端技術有興趣的話,也歡迎免費訂閱《古古的後端筆記》電子報,每週二為你送上一篇後端技術分享,那我們就下一篇文章見啦!
補充:我開設的 Spring Boot 零基礎入門、Spring Security 零基礎入門、GitHub 免費架站術 已在 Hahow 平台上架啦!輸入折扣碼「HH202603KU」即可享 83 折優惠 。